
Executive summary: Complex control layers with separate EMS and PPC systems introduce delays at each handoff that can cause assets to fail qualification tests; this post explores how integrated control on unified hardware eliminates latency sources, enabling sub-second response times and access to ancillary markets.
Throughout this series, we’ve examined how fragmented control architectures create compounding challenges in solar-plus-storage projects. We started with multivendor coordination — how conflicting control philosophies stretch commissioning and compromise performance. We then explored the grid services gap — how control systems designed for standalone solar or storage assets lack the logic to optimize hybrid resources, resulting in poor coordination during critical grid events.
Both challenges reveal architectural mismatches, but today we’re examining a performance consequence measured in sub-seconds rather than months. When separate EMS and PPC systems must coordinate through multiple communication layers, the handoffs that enable coordination also introduce delays. In fast frequency response markets where grid operators demand sub-second response times, those delays become the difference between qualification and failure.
Challenge
Control Layer Complexity
Control Signal Latency
Modern grid operators increasingly demand frequency and voltage support from assets requiring assets to detect grid disturbances and respond with sub-second speed. Meeting these requirements isn’t just about having capable hardware—it’s about how quickly your control system can orchestrate that hardware.
In traditional hybrid architectures, control signals travel through multiple layers before reaching the equipment:
- Grid frequency deviation is detected by monitoring equipment
- Signal passes to the plant-level EMS for processing
- EMS calculates required response and sends commands to the PPC
- PPC translates high-level commands into inverter-specific setpoints
- PPC communicates with PV inverters via one protocol and BESS via another
- Inverters finally execute the response
Each handoff introduces latency—communication delays, protocol translations, data buffering, and processing time. What should be a near-instantaneous response becomes a relay race where milliseconds accumulate at every exchange. When your EMS and PPC exist as separate systems, potentially from different vendors running on different hardware platforms, you’ve architected latency into your control system before a single MW flows.

Impact
Fast Grid Responses Become Difficult
The consequences of control latency show up most clearly during Fast Frequency Response (FFR) capability testing. Assets that should theoretically meet response time requirements fail qualification because control latency consumes too much of the allowable window—the hardware is capable, but the control architecture is not. Projects that budgeted for FFR revenue streams discover they can’t qualify for the services they were designed to provide.
This qualification challenge creates a cascade of economic impacts:
- Degraded service performance: Even when assets manage to pass initial testing, excessive latency leads to slower, less accurate responses during actual grid events, translating directly to reduced service payments under performance-based contracts where speed and accuracy determine compensation.
- Revenue opportunity cost: Assets miss premium payments that markets increasingly offer for faster response times—opportunity costs that compound throughout the project’s operational life.
- Grid code non-compliance risk: As grid codes evolve to require faster response times, assets with high-latency control architectures face obsolescence risk. What meets today’s requirements may fail tomorrow’s, creating stranded asset risk when grid operators tighten performance standards.
Solution Framework
Integrated Control on Unified Hardware
The path to minimizing latency requires eliminating unnecessary control layers entirely.
An integrated approach co-locates EMS and closed-loop PPC functionality on the same hardware platform. Rather than treating energy management and power plant control as separate systems that must communicate, this architecture embeds both functions within a unified control framework.
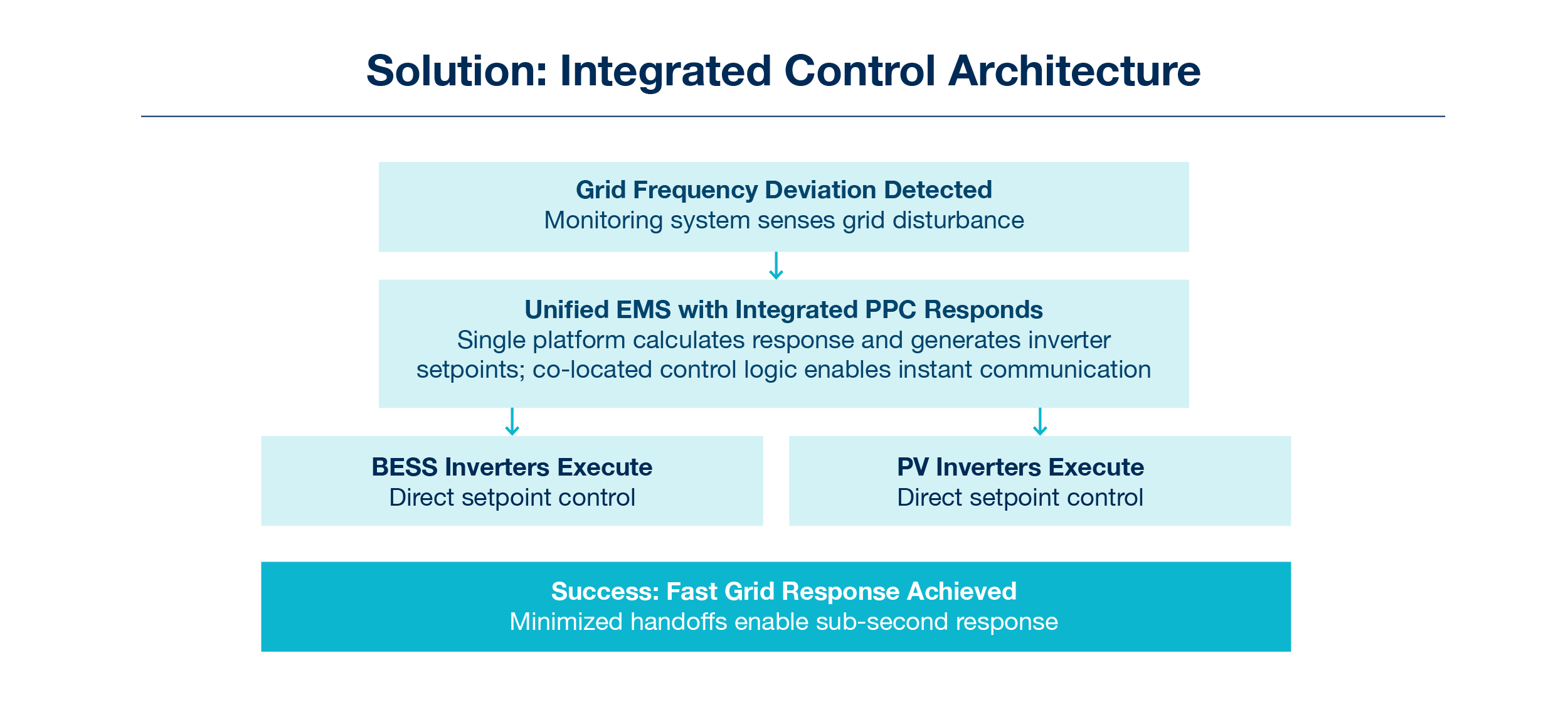
The streamlined signal path looks dramatically different:
- Grid frequency deviation detected
- Unified controller rapidly processes EMS logic and generates inverter setpoints
- Commands dispatched directly to PV and BESS equipment
By eliminating the handoff between EMS and PPC, you remove multiple sources of latency: inter-system communication delays, protocol conversions, redundant data processing, and the coordination overhead of synchronizing separate control systems. The control logic that understands hybrid asset optimization and the control logic that commands individual inverters exist in the same computational space, enabling near-instantaneous response orchestration.
Key Benefits
Proactive Grid Response Without Coordination Overhead
Integrated control architecture enables sub-second response times that exceed most current grid code requirements, future-proofing assets for premium fast response markets and tightening standards. With no coordination layer between EMS and PPC, there’s greatly reduced possibility of communication timeouts or synchronization errors. When your control architecture is designed for speed from the ground up, FFR revenue streams move from uncertain to bankable.
Key Takeaways & Recommendations for Developers
Evaluate control latency as a qualification risk, not just a performance metric by:
- Requesting end-to-end response time testing data from similar projects, measured from grid signal detection to inverter execution
- Asking vendors to map the complete control signal path. You can count the communication hops and protocol translations between grid event detection and equipment response
- Verifying whether EMS and PPC functions run on unified hardware or require inter-system communication that introduces latency
- For projects targeting FFR or other fast-response services, building latency testing into factory acceptance criteria before equipment ships
- Work with integrators who understand the timing requirements for your target revenue streams; verify they’ve successfully qualified similar projects for FFR or other fast-response services, as some communication protocols simply can’t meet the necessary response windows
Next up: We’ve seen how fragmented control architectures create coordination delays, limit grid services, and introduce latency that causes qualification failures. These challenges share a common root cause: control architecture decisions made too late in development. In our final post, we’ll provide a practical framework for evaluating architecture options early, when you can still optimize project performance and revenue.